Introduction
If you’ve been anywhere near a marketing analytics conversation in the last few years, you’ve heard the term “Marketing Mix Modeling” (or MMM) thrown around. A lot. It’s gone from a niche econometric technique that media agencies ran once a year to something every data-driven marketing team is expected to have an opinion on.
But what actually is it? And why should you care in 2026?
I’ve been building marketing mix models for over a decade. First at Blackwood Seven (which was acquired by Kantar), then at Alviss AI, where we’ve spent years turning what used to be a slow, consultant-heavy process into something that runs continuously and actually helps people make decisions. So I have some opinions. But before we get to opinions, let’s start with the fundamentals.
The core idea
Marketing Mix Modeling is, at its heart, a statistical method for answering a deceptively simple question: which of the things I’m spending money on are actually working, and by how much?
You take historical data on your business outcomes (revenue, conversions, signups, whatever matters to you) and your marketing activities (media spend, impressions, GRPs, campaign flights) along with external factors that also affect your business (seasonality, weather, competitor activity, economic indicators). Then you build a model that separates the contribution of each driver.
That’s it. That’s the core idea.

Ok fine, but why is this hard? Because these signals are tangled together in the real world. You run TV and digital simultaneously. Sales go up in December regardless of what you do. A competitor launches a price war in Q3. A new product hits the shelves in the same week you increase your social spend. The model’s job is to disentangle all of this and give you a credible estimate of what each factor actually contributed.
How it actually works
Let’s walk through the mechanics without getting too deep into the math (we’ll save that for a future post on response curves and adstock).
At the most basic level, an MMM is a regression model. You’re predicting your KPI (let’s say weekly revenue) as a function of your marketing inputs and control variables. Something like:
\[ \text{Revenue}_t = \text{Base}_t + f(\text{TV}_t) + f(\text{Digital}_t) + f(\text{Search}_t) + \ldots + \text{Controls}_t + \varepsilon_t \]
Where \(\text{Base}_t\) captures the revenue you’d get even with zero marketing (brand strength, distribution, organic demand), each \(f(\cdot)\) is a transformation of a media channel that accounts for how advertising actually behaves, \(\text{Controls}_t\) captures external factors, and \(\varepsilon_t\) is the stuff the model can’t explain.
Now, those \(f(\cdot)\) transformations are where the real modeling happens. Two concepts matter here:
Adstock (or carryover): When you see a TV ad today, it doesn’t just affect your behavior today. It lingers. You might buy something next week because of an ad you saw three weeks ago. Adstock transformations model this decay, the idea that advertising has a half-life. The shape of that decay varies by channel. TV tends to have longer carryover than paid search, for example.
Saturation (or diminishing returns): Doubling your spend on a channel does not double your return. At some point, you’re hitting the same people too many times, or you’ve already captured the easy conversions. Response curves model this saturation, and they’re critical for optimization because they tell you where each additional dollar starts to lose its punch.
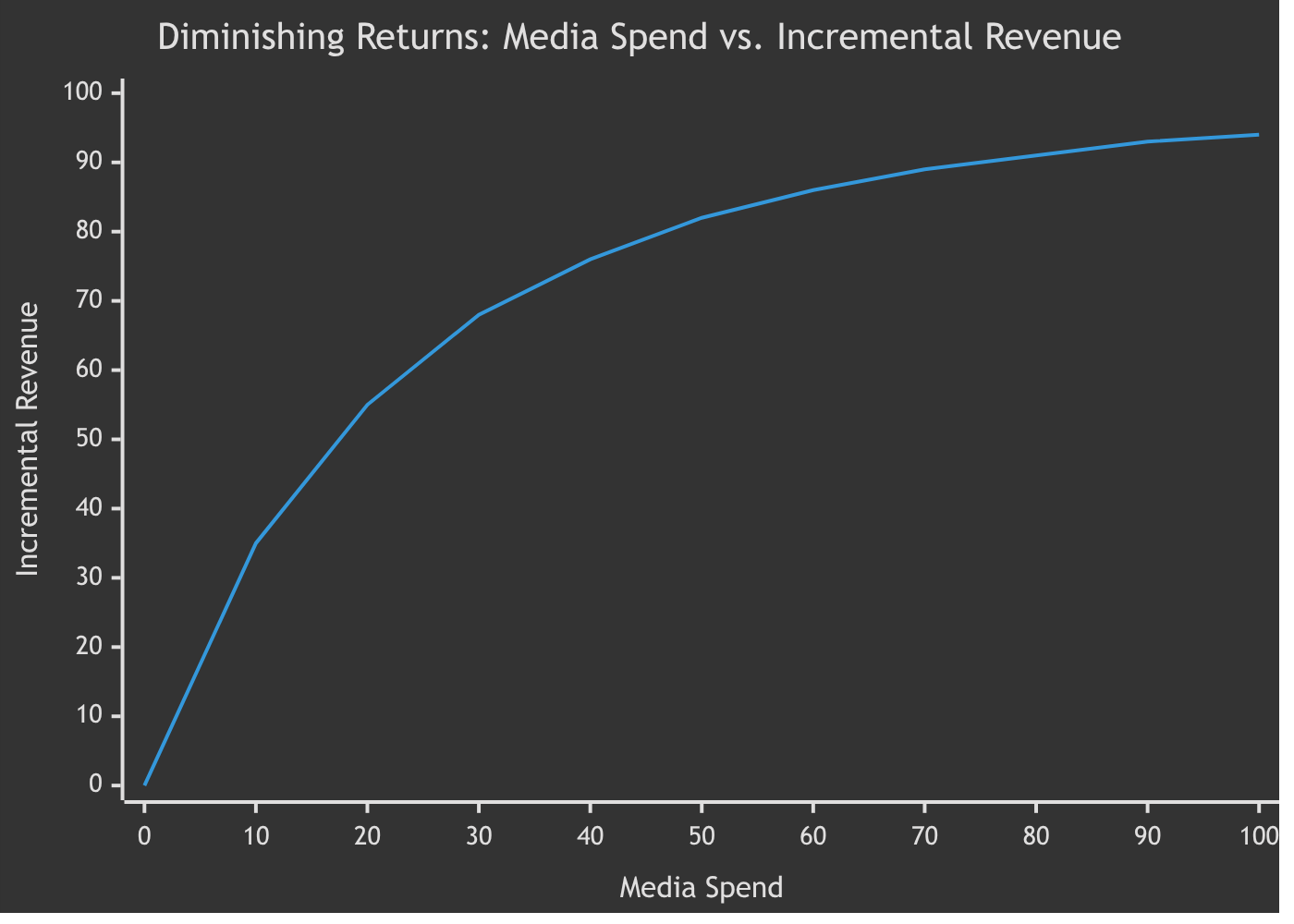
Get these two things right, and you have a model that can decompose your revenue into contributions from each channel and external factor. Get them wrong, and you’re just doing expensive curve fitting.
Why MMM is back (and why it never really left)
MMM has been around since the 1960s. It was the standard approach for decades, then fell somewhat out of fashion when digital marketing arrived with its promise of tracking every click and attributing every conversion. Multi-touch attribution (MTA) became the shiny new thing.
So what happened? Reality happened.
Third-party cookies are effectively dead. Apple’s App Tracking Transparency gutted mobile attribution. Privacy regulations (GDPR, CCPA, and their descendants) have made user-level tracking increasingly difficult and legally risky. The “track everything” model of MTA has been eroding for years, and in 2026 there’s no pretending it’s coming back.
But the need to understand what drives your business hasn’t gone anywhere. If anything, it’s more urgent. Marketing budgets are under more scrutiny than ever, and CFOs want answers that go beyond “the algorithm says so.”
MMM doesn’t need cookies. It doesn’t need user-level tracking. It works with aggregated data (spend by week, impressions by channel) that you already have. It works for offline channels that MTA never could touch. And modern MMM, built on Bayesian inference rather than the frequentist regressions of the 1990s, can quantify uncertainty in a way that actually helps decision-makers understand what they know and what they don’t.
Classical MMM vs. modern Bayesian MMM
This is where it gets interesting, and where a lot of the confusion in the market lives.
Classical MMM, the kind that consulting firms have been running for decades, typically uses ordinary least squares (OLS) regression or some variant. You throw your data in, you get point estimates out, and you hope the confidence intervals are narrow enough to be useful. The model runs once, maybe twice a year. It takes months. It costs a lot.
Modern MMM is different in a few important ways:
Bayesian inference: Instead of just getting point estimates, you get full probability distributions over your parameters. This means you can say “we’re 90% confident that TV contributes between 8% and 14% of revenue” rather than “TV contributes 11%.” That range matters. It’s the difference between a number someone prints on a slide and a number someone actually uses to make a decision.
Prior knowledge: In a Bayesian framework, you can encode what you already know. If you know that TV doesn’t have a negative effect on sales (that would be pretty weird), you can build that into the model. If you have results from previous quarters, you can use them to inform the current model. This isn’t cheating. It’s being honest about the information you have. The prior should reflect your knowledge, not be adapted to fit your data.
Frequent updates: There’s no reason to wait six months between model runs. Modern platforms (including ours at Alviss AI) refit models daily or weekly as new data arrives. This turns MMM from a periodic strategic exercise into a continuous decision-support system.
Uncertainty-aware optimization: When you optimize budget allocation, the uncertainty matters. A channel with high average ROI but massive uncertainty is a very different bet than one with moderate ROI and tight confidence. Bayesian MMM gives you the information to make that distinction. Classical MMM doesn’t.
What MMM can (and can’t) tell you
Let’s be honest about both sides.
MMM is good at:
- Measuring the incremental contribution of each marketing channel to your business outcomes
- Estimating ROI and marginal ROI by channel
- Optimizing budget allocation across channels
- Capturing offline media effects (TV, radio, print, OOH) that digital attribution misses entirely
- Providing a privacy-compliant measurement framework
- Separating marketing effects from external factors like seasonality and economic trends
MMM is less good at:
- Real-time, campaign-level optimization (it works at a higher level of granularity, typically weekly or biweekly)
- Measuring creative effectiveness within a channel (it tells you “digital display drove X” but not which specific banner did the work)
- Working with very short data histories (you generally need 2-3 years of data for reliable estimates)
- Establishing true causality without experimental validation (it’s still an observational model, even if a good one)
Anyone who tells you MMM solves everything is selling you something. But for the question “how should I allocate my marketing budget across channels to maximize business outcomes,” it’s the best tool we have. Especially now that the alternatives have had their legs cut out from under them.
Where MMM fits in your measurement stack
MMM doesn’t replace everything else. It works best as part of a broader measurement approach:
MMM gives you the top-down, strategic view: which channels are working, how much to spend where, and what the diminishing returns look like.
Experiments (geo-lift tests, A/B tests, incrementality tests) give you causal validation. They’re the ground truth that calibrates your MMM. If your model says paid social drives 15% of incremental revenue, a geo-lift test can confirm or challenge that estimate. The best MMM implementations feed experimental results back into the model as calibration priors.
Attribution tools (whatever survives the privacy transition) give you the granular, tactical view within digital channels: which campaigns, audiences, and creatives are performing.

Think of MMM as the map, experiments as the ground surveys, and attribution as the GPS. You need all three, but the map is what you plan with.
Getting started with MMM
If you’re considering MMM for your organization, here’s what I’d think about:
Data readiness: You need historical data on your KPI and marketing activities, ideally 2-3 years at weekly granularity. You also need data on external factors: holidays, promotions, competitor activity, macroeconomic indicators. The quality of your MMM is directly proportional to the quality and granularity of your data.
Model transparency: Insist on understanding what’s inside the model. Can you see the response curves? The adstock parameters? The prior distributions? If a vendor hands you a black box with numbers coming out, walk away. I myself despise black boxes. The whole point of MMM is to build understanding, not to replace one opaque system with another.
Bayesian or bust: In 2026, there’s no good reason to use frequentist MMM. The Bayesian approach gives you uncertainty quantification, the ability to encode prior knowledge, and more stable estimates with limited data. If your vendor is still running OLS regressions, they’re a decade behind.
Continuous, not annual: The old model of running MMM once a year is dead. Markets move too fast. Your model should update as new data comes in, giving you a living view of performance rather than a stale snapshot.
Validation through experiments: Budget for geo-lift tests or other incrementality experiments to calibrate your model. An MMM without experimental validation is an opinion with math around it.
Conclusion
Marketing Mix Modeling is the most practical, privacy-compliant, and methodologically sound way to understand what drives your business outcomes and how to allocate your marketing budget. It’s been around for decades, but the modern Bayesian incarnation is a fundamentally different (and better) animal than what agencies were running in the 2000s.
The question isn’t whether you need MMM. If you’re spending meaningful money on marketing across multiple channels, you do. The question is whether you’re going to build it yourself, use an open-source framework, or work with a platform that handles the infrastructure, the modeling, and the continuous updates for you.
At Alviss AI, we’ve built our platform around Bayesian MMM with daily model refitting, full model transparency, and uncertainty-aware optimization. Not because it’s trendy, but because after a decade of building these models, we know it’s the right way to do it. If you want to see what that looks like in practice, get in touch.